我們之前講到那些方法幾乎都是透過尋找標籤下的{key: value},今天要介紹的這種方式不同於前面的那些方法,他是透過節點下去做查詢,這個方式就叫做XPath
是一種用於在XML文檔中定位和選取元素的語言。廣泛用於解析和操作XML文檔、HTML文檔,以及其他具有樹狀結構的數據格式。XPath提供了一種方便和強大的方式來導航XML文檔並選取所需的數據。
以下是XPath的一些重要概念和特點:
節點(Node): 在XML文檔中,所有的元素、屬性、文本、註釋等都被視為節點。XPath中有不同的節點類型,如元素節點、屬性節點、文本節點等。
路徑表達式(Path Expression): XPath使用路徑表達式來描述從根節點到目標節點的路徑。路徑可以使用斜杠 / 分隔節點,例如 /root/element/subelement。// 是一個特殊的符號,表示搜索整個文檔中的節點。
選擇節點(Node Selection): XPath可以通過路徑表達式選取特定的節點。例如,/root/element 將選取根節點下名為 "element" 的所有節點。
軸(Axis): 軸指定節點與其他節點的關係,如子節點、父節點、同層節點等。常見的軸包括 child、parent、ancestor、following-sibling 等。
過濾條件(Predicate): 可以在路徑表達式中使用方括號 [] 來添加過濾條件,以進一步限制選取的節點。例如,/root/element[@attr='value'] 將選取具有指定屬性值的 "element" 節點。
選取屬性值: 使用 @ 符號來選取節點的屬性值,例如 //element/@attr。
再來我們簡單看一下如何操作網頁上面的XPath
請記得瀏覽器必須使用自己下載的webdriver,否則網頁架構是有可能不同的
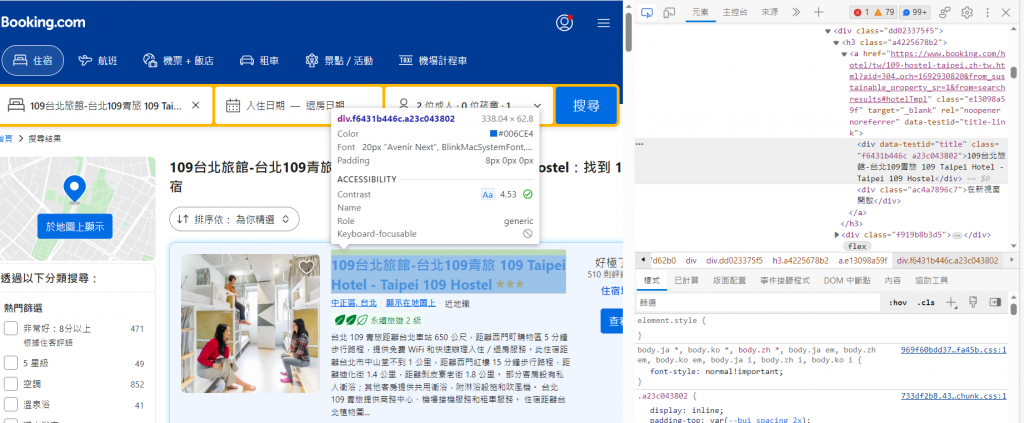
沒錯還是那個booking,首先我們得先提取出網站上面的XPath,透過選取的游標,選一下自己想要的title
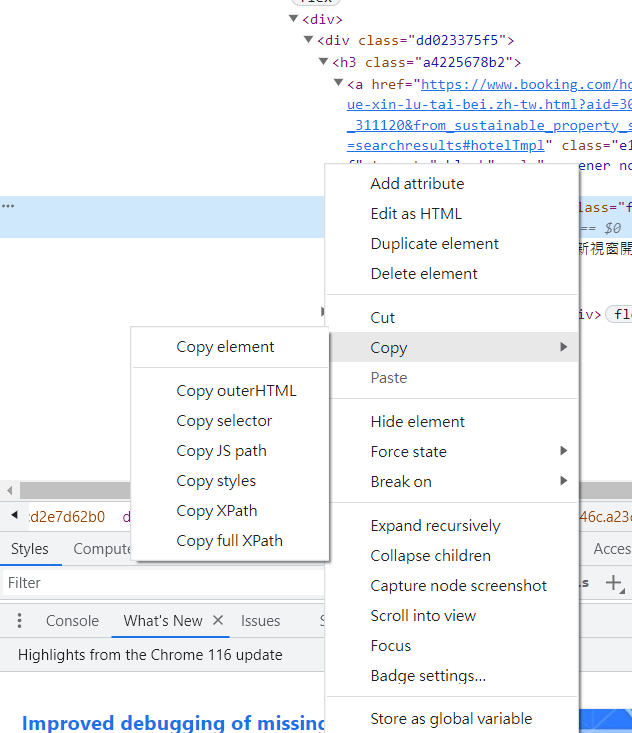
對著那個深色的div點右鍵,按下Copy後有一個Copy XPath,點下去就對了!!!
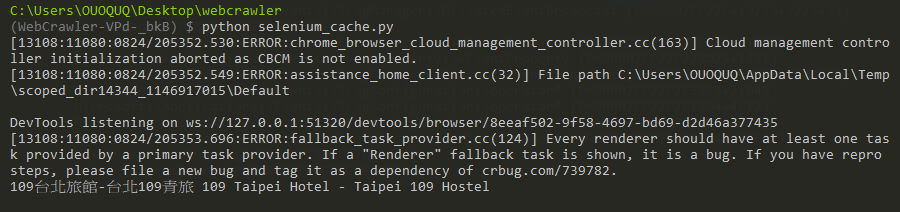
有了之後我們就可以開始寫python了
#(前面一樣直接省略,忘掉的人罰你回去複習[Day 09])
path = '//*[@id="search_results_table"]/div[2]/div/div/div[3]/div[2]/div[1]/div[2]/div/div[1]/div/div[1]/div/div[1]/div/h3/a/div[1]'
title = driver.find_element(By.XPATH, path)
print(title.text)
我們可以看到,雖然XPath可以透過節點去找到檔案位置,但是這在動態網頁其實是非常不穩定的,如果今天網頁因為一點點的浮動而造成沒有辦法讀取而崩潰,是非常影響整體程式運行的,但是如果這個指定的位置是穩定的,他將會非常方便,可以透過For Loop找到每個想要的位置,參數的調整也會很方便,比如我只想要前五家飯店,可以自訂一個輸入讓自己可以隨意調整輸入的數量。
如果在靜態的部分可以考慮使用XPath,但是如果是動態方面的話建議還是使用搜尋標籤的方式來執行會方便些。
下一篇來實際操作selenium和beautifulsoupy在查詢上面的方便性

